こんにちは、ゆうじ(@yuji_sgs_prog)です。
本記事では、下記記事で紹介した深層学習モデルを活用して、逆解析していくアルゴリズムについてまとめていきます。

そもそも逆解析とは何か?や、機械学習モデルを活用して逆解析していく原理についても紹介していくので、興味ある方はぜひ最後までご覧ください。
理系の大学・大学院生は「TECH-BASE」による機械学習スキルの習得がおすすめです。カリキュラムから学習支援、就活のサポートまで全て無料で受講できるため、お得に市場価値の高いスキルを身につけてキャリア形成に役立てていきましょう。
機械学習モデルの逆解析とは?

そもそも機械学習モデルの逆解析とは、広い意味でいうと「出力から入力を予測すること」です。
- 目標の売り上げを達成していくために、どれだけの広告予算が必要になるかを予測
- ユーザーが優良顧客になるために、どのようなアプローチを測れば良いのかを予測
- 材料開発分野において欲しい物性を定めた際に、それを実現するための材料や構造を予測
上記のように、「欲しい結果」を先に定めて、それを実現していくための「手段や条件は何か?」を予測していくのが逆解析です。
ここで逆解析についての説明は終了しますが、より深く理解したい方は下記記事も参考にしてみると良いかもしれません。
機械学習モデルの逆解析を行なっていく準備・環境

機械学習モデルの逆解析を行なっていく準備・環境については下記の通り。
- Google Colaboratoryにて実行
- データセットは3列×10,000行のcsvデータ(自前csvファイルはこちら。※クリックするとダウンロードします)
- Kerasを使って深層学習モデルで学習後、その学習済みモデルを適用して逆解析を行なっていく
データセットについては1, 2列目をインプットに、3列目をアウトプットとして深層学習モデルを構築します。
その後、3列目の欲しいパラメータ設定した際に、最適な1, 2列目のパラメータを探索するよう逆解析していきます。
機械学習モデルの逆解析を実装したコードを解説

それでは機械学習モデルの逆解析を実装したコードを解説していきます。
また、実装したコードはipynb形式でGitHubに上げています。
①:Kerasで深層学習モデルを構築
ここの部分は以前上げた記事にまとめているため、本記事での説明は省かせていただきます。
詳しい内容については下記記事をご覧ください。
②:逆解析の実装
ここが本記事の一番肝の部分でして、逆解析を実行していくためのプログラムは以下の通り。
import tensorflow as tf
# 出力の所望値を設定
target_y = tf.constant([4.0], dtype=tf.float32)
# 初期の入力値をランダムに設定(x1は0から10の範囲、x2は0から1の範囲に制限)
x1 = tf.Variable(tf.random.uniform([1], 0, 10))
x2 = tf.Variable(tf.random.uniform([1], 0, 1))
# 最適化手法を定義
optimizer = tf.keras.optimizers.Adam(learning_rate=0.01)
# 各値を保存するリスト
x1_values = []
x2_values = []
# 目的関数の値を保存するリスト
objective_values = []
# 学習回数
step = 1000
# パラメータ更新を実行
for step in range(step):
# 勾配計算を行うためのAPI
with tf.GradientTape() as tape:
# モデルの出力を定義(予測値を計算)
predicted_y = model(tf.stack([x1, x2], axis=1))
# 目的関数を定義(予測値と目標値の二乗誤差を計算)
objective = tf.square(predicted_y - target_y)
# 勾配を計算(目的関数に対する各パラメータx1とx2の勾配を計算)
gradients = tape.gradient(objective, [x1, x2])
# 最適化手法を適用(計算された勾配を使用してパラメータx1とx2を更新)
optimizer.apply_gradients(zip(gradients, [x1, x2]))
# 各値を保存
x1_values.append(x1.numpy()[0])
x2_values.append(x2.numpy()[0])
# 目的関数の値を保存
objective_values.append(objective.numpy()[0][0])
# 10ステップごとに結果を出力
if step % 10 == 0:
print(f'Epoch: {step}, Loss: {objective.numpy()[0][0]}, x1: {x1.numpy()}, x2: {x2.numpy()}')
# 最終的な学習結果を出力(x1とx2のパラメータ)
print(f'Loss: {objective.numpy()[0][0]}, x1: {x1.numpy()}, x2: {x2.numpy()}')何をしているのか簡潔にまとめると、
- 出力(y)の所望値を設定する
- 入力パラメータ(x1, x2)をランダムに設定する
- 学習済みモデルに②で設定したパラメータを入力する | f(x1, x2)
- ③−①の2乗を目的関数として定義 | objective = (f(x1, x2) – y)^2
- ④で設定した目的関数の勾配計算を行う | ∇(f(x1, x2) – y)^2
- 勾配計算で得たベクトルと学習率(α)を掛け合わせて、入力パラメータを更新
x1_new = (x1 – α∇(f(x1, x2) – y)^2), x2_new = (x2 – α∇(f(x1, x2) – y)^2 - 目的関数が小さくなるような入力パラメータ(x1_new, x2_new)が得られるまで繰り返し計算
上記の計算を行なっているというわけです。(以下にもう少し分かりやすく解説しています。)
このプログラムを実行すると、次のように計算が進みます。
Epoch: 0, Loss: 12.378057479858398, x1: [5.4730206], x2: [0.8441667]
Epoch: 10, Loss: 10.071893692016602, x1: [5.5738754], x2: [0.7438492]
Epoch: 20, Loss: 7.583127498626709, x1: [5.6813836], x2: [0.64221096]
.
.
.
Epoch: 990, Loss: 5.46265255252365e-11, x1: [8.027802], x2: [0.21042259]
Loss: 5.46265255252365e-11, x1: [8.027802], x2: [0.21042259]目的関数の値(Loss)が十分小さいときのx1, x2が欲しい値となります。
③:結果の可視化
逆解析によって、入力パラメータが更新されていった際の目的関数の値をグラフで可視化してみましょう。
from mpl_toolkits.mplot3d import Axes3D
# x,y,zに要素追加
x = np.array(x1_values)
y = np.array(x2_values)
z = np.array(objective_values)
# Figureを追加
fig = plt.figure()
ax = fig.add_subplot(111, projection='3d')
# Axesのタイトルを設定
ax.set_title("Inverse_Analysis", size = 18)
# 軸ラベルを設定
ax.set_xlabel("x1", size = 14, color = "r")
ax.set_ylabel("x2", size = 14, color = "r")
ax.set_zlabel("Loss", size = 14, color = "r")
ax.scatter(x1_values, x2_values, objective_values)
plt.show()上記プログラムを実行した結果は以下の通り。
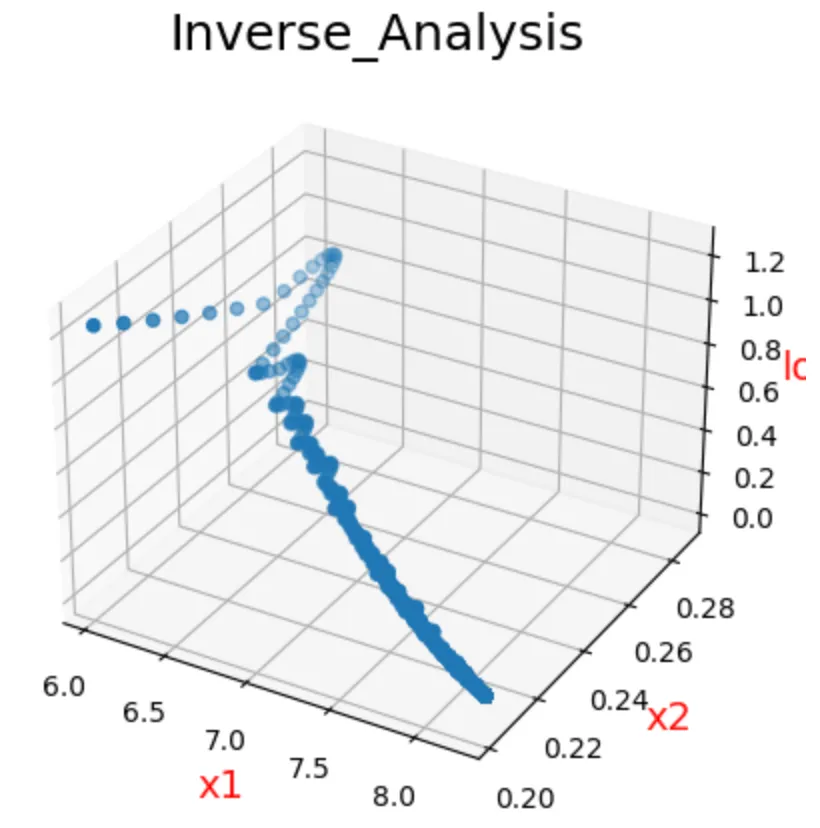
x1, x2の入力パラメータが更新されていく度に、目的関数の値(Loss)が減っていることがわかります。
機械学習モデルの逆解析の原理を解説

ここでは逆解析の実装部分についてより解像度を上げて説明していきます。
実装部分では長々と書きましたが、逆解析で行なっていることは以下の2つ。
- 目的関数を定義
- 定義した目的関数を減らしていく
順番に解説していきます。
①:目的関数を定義
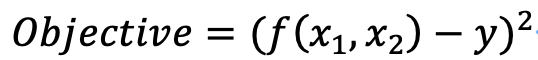
上式について簡単に説明すると、f()は学習済みモデル、x1, x2は入力パラメータ、yは欲しい出力値です。
この目的関数が0になれば、そのときのx1, x2が求めたい入力パラメータとなります。
②:定義した目的関数を減らしていく
では、どうすれば目的関数を減らすようなx1, x2を探すことができるのでしょうか?
結論からいうと目的関数を減らすには、以下のことを行なっていきます。
- x1, x2時点での目的関数の勾配計算により、x1, x2を変化させる方向性(増やすか減らすか)を決める
- どれだけx1, x2を変化させるかは学習率というハイパーパラメータで決める
①について、x1, x2時点での目的関数の勾配計算をすることで、目的関数を減らすようなベクトルが求まります。
②について、目的関数を減らせるベクトルが分かれば、後はその方向にパラメータを変化させるだけです。そこで、どれだけ変化させるかを学習率であらかじめ決めているわけです。
ここの部分については、「【決定版】スーパーわかりやすい最適化アルゴリズム -損失関数からAdamとニュートン法-」の記事を読むとより深く理解できると思うので、ぜひあわせて読んでみてください。
機械学習モデルの逆解析まとめ

本記事では、機械学習モデルの逆解析についてまとめました。
1つの出力に対する逆解析は本記事の手法で実現できるので、興味ある方はぜひ実装していただければと思います。
また、複数出力に対する逆解析は本記事で紹介した手法だけでは上手くいかず、もう一捻り工夫が必要です。(多目的最適化問題に発展するため)
そちらの記事についても後々アウトプットできればいいなぁ〜という感じで本記事は終了します(*`・ω・)ゞ
というわけで、最後まで読んでいただきありがとうございました。