

こんにちは、ゆうじ(@yuji_sgs_prog)です。
Kerasで回帰ニューラルネットワークを実装してみた【Sequentialモデル】の応用編です。

上記の記事では、単純かつシンプルなSequentialモデルを構築しているのですが、本記事ではFunctional APIを使ってKerasで複数出力する回帰モデルを構築していきます。
Kerasを活用して、ニューラルネットワークによる回帰分析を行いたい方は参考になると思うので、ぜひご覧ください(*`・ω・)ゞ
理系の大学・大学院生は「TECH-BASE」による機械学習スキルの習得がおすすめです。カリキュラムから学習支援、就活のサポートまで全て無料で受講できるため、お得に市場価値の高いスキルを身につけてキャリア形成に役立てていきましょう。
Kerasで複数出力する回帰モデルを構築する前に

前回の記事同様、いきなりモデルの構築に入るのではなく、事前準備や環境について紹介していきます。
- Google Colaboratoryにて実行
- データセットは4列×10,000行のcsvデータ(自前csvファイルはこちら。※クリックするとダウンロードします)
- Functional APIを使って、2つの出力を得る
データセットについては1, 2列目をインプットに、3, 4列目をアウトプットとしてニューラルネットワークを構築します。
本記事で構築するモデルのイメージ図は以下の通りです。
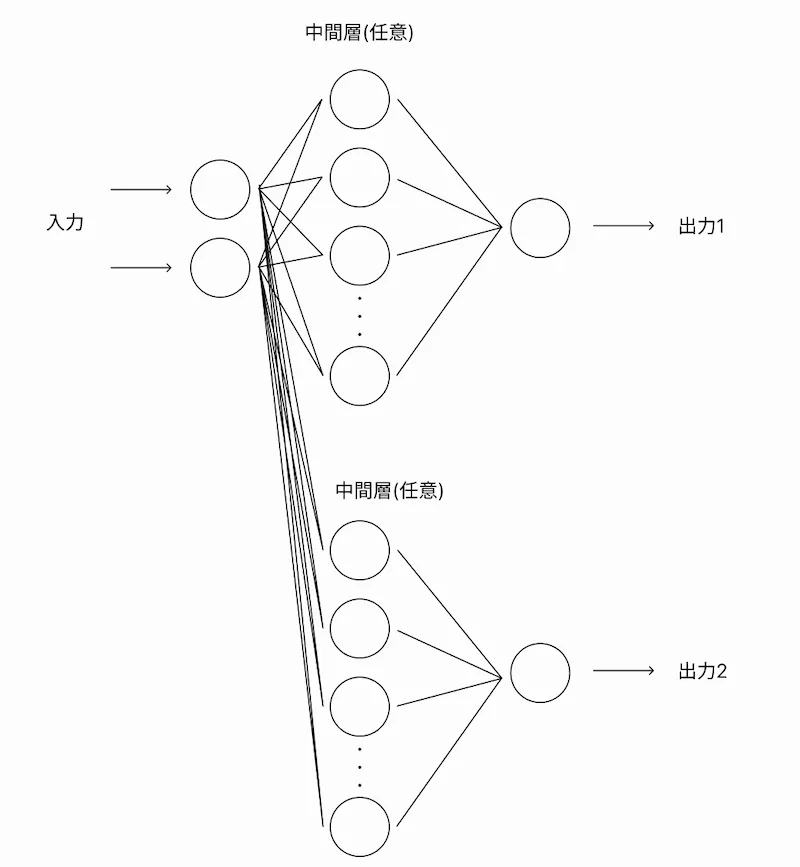
Kerasで複数出力する回帰モデルを構築したコードを解説

実装したコードの全体像をまず紹介します。
なお、実装したコードはipynb形式でGitHubに上げているので、そちらも参考にしていただければと思います。
# 使用するライブラリをインポート
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import io
from google.colab import files
from sklearn.model_selection import train_test_split
from keras.layers import Dense, Activation
from keras.optimizers import Adam
from keras.callbacks import EarlyStopping, LearningRateScheduler
from keras.models import Model
from keras.layers import Input, Dense
from sklearn.metrics import mean_absolute_error
from sklearn.metrics import mean_squared_error
from math import sqrt
from sklearn.metrics import r2_score
# Google Colaboratoryでファイルをアップロード
uploaded = files.upload()
# データフレームとして、変数dfに4列×10000行のデータを格納
df = pd.read_csv(io.BytesIO(uploaded['Multiple-Outputs.csv']))
# データの分割
(train, test) = train_test_split(df, test_size=0.2, shuffle=True)
# x_train, x_testではcsvファイルの1列目から2列目を,y_train, y_testでは3, 4列目のデータを活用
x_train = train.iloc[:, [0, 1]]
y_train = train.iloc[:, [2, 3]]
x_test = test.iloc[:, [0, 1]]
y_test = test.iloc[:, [2, 3]]
# データの正規化
x_train = (x_train - x_train.min()) / (x_train.max() - x_train.min())
x_test = (x_test - x_test.min()) / (x_test.max() - x_test.min())
# モデルの構築
# inputの数:x1, x2
inputs = Input(shape=(2,))
# 学習回数
epochs = 100
batch_size = 64
# ノード数
node = 64
x1 = Dense(node, activation='relu')(inputs)
x2 = Dense(node, activation='relu')(x1)
x3 = Dense(node, activation='relu')(x2)
x4 = Dense(node, activation='relu')(x3) # アウトプット直前の層
output1 = Dense(1, name='output1')(x4)
x5 = Dense(node, activation='relu')(x3) # アウトプット直前の層
output2 = Dense(1, name='output2')(x5)
model = Model(inputs=inputs, outputs=[output1, output2])
optimizer = Adam(lr=0.001, beta_1=0.9, beta_2=0.999)
model.compile(
optimizer=optimizer,
loss=['mse', 'mse']
)
# 学習オプション
history = model.fit(x_train,
{"output1":y_train.iloc[:, [0]], "output2":y_train.iloc[:, [1]]},
epochs=epochs,
batch_size=batch_size,
validation_data=(x_test, {"output1":y_test.iloc[:, [0]], "output2":y_test.iloc[:, [1]]})
)
# 構築したモデルで予測
pred1, pred2 = model.predict(x_test)
#精度評価指標
# Output1 ====================================================================
print("======= Output1 =======")
# MAE
test_MAE = mean_absolute_error(y_test.iloc[:, 0], pred1)
print('MAE:', test_MAE)
# RMSE
test_RMSE = sqrt(mean_squared_error(y_test.iloc[:, 0], pred1))
print('RMSE:', test_RMSE)
# 決定係数
R2 = r2_score(y_test.iloc[:, 0], pred1)
print('R2:', R2)
print("")
# Output2 ====================================================================
print("======= Output2 =======")
# MAE
test_MAE = mean_absolute_error(y_test.iloc[:, 1], pred2)
print('MAE:', test_MAE)
# RMSE
test_RMSE = sqrt(mean_squared_error(y_test.iloc[:, 1], pred2))
print('RMSE:', test_RMSE)
# 決定係数
R2 = r2_score(y_test.iloc[:, 1], pred2)
print('R2:', R2)
# Figureを追加
fig = plt.figure(figsize = (15, 5))
# Output1 ====================================================================
# 1×2 の1枚目に描画する
loss_graph1 = fig.add_subplot(1, 2, 1)
# x,yに要素追加
loss1 = history.history['output1_loss']
val_loss1 = history.history['val_output1_loss']
epochs1 = len(loss1)
# グラフ設定
loss_graph1.plot(range(epochs), loss1, marker='.', label='loss')
loss_graph1.plot(range(epochs), val_loss1, marker='.', label='val_loss')
loss_graph1.set_title("Loss_Output1", size = 18)
loss_graph1.legend(loc='best')
loss_graph1.grid()
loss_graph1.set_xlabel("epochs", size = 14, color = "r")
loss_graph1.set_ylabel("loss", size = 14, color = "r")
#==============================================================================
# Output2 ====================================================================
# 1×2 の2枚目に描画する
loss_graph2 = fig.add_subplot(1, 2, 2)
# x,yに要素追加
loss2 = history.history['output2_loss']
val_loss2 = history.history['val_output2_loss']
epochs2 = len(loss2)
# グラフ設定
loss_graph2.plot(range(epochs), loss2, marker='.', label='loss')
loss_graph2.plot(range(epochs), val_loss2, marker='.', label='val_loss')
loss_graph2.set_title("Loss_Output2", size = 18)
loss_graph2.legend(loc='best')
loss_graph2.grid()
loss_graph2.set_xlabel("epochs", size = 14, color = "r")
loss_graph2.set_ylabel("loss", size = 14, color = "r")
#==============================================================================
# Observed-Predicted Plot
# Figureを追加
fig = plt.figure(figsize = (15, 5))
# Output1 ====================================================================
# 1×2 の1枚目に描画する
yy1 = fig.add_subplot(1, 2, 1)
yy1.scatter(y_test.iloc[:, 0], pred1, c='blue', alpha=0.8)
# グラフ設定
yy1.set_title("observed_predicted1", size = 18)
yy1.grid()
yy1.set_xlabel("observed_data", size = 14, color = "r")
yy1.set_ylabel("predicted_data", size = 14, color = "r")
# Output2 ====================================================================
# 1×2 の2枚目に描画する
yy2 = fig.add_subplot(1, 2, 2)
yy2.scatter(y_test.iloc[:, 1], pred2, c='blue', alpha=0.8)
# グラフ設定
yy2.set_title("observed_predicted2", size = 18)
yy2.grid()
yy2.set_xlabel("observed_data", size = 14, color = "r")
yy2.set_ylabel("predicted_data", size = 14, color = "r")だいぶ長めですが、前回の記事と違う部分をピックアップしてご紹介していきます。
ライブラリのインポート
from keras.models import Model
from keras.layers import Input, DenseこれがKerasで複数出力する際に必要となってくるライブラリです。
モデル構築の部分で「Sequentialモデル」とは別のライブラリをインポートする必要があります。
アウトプットを複数へ
# x_train, x_testではcsvファイルの1列目から2列目を,y_train, y_testでは3, 4列目のデータを活用
x_train = train.iloc[:, [0, 1]]
y_train = train.iloc[:, [2, 3]]
x_test = test.iloc[:, [0, 1]]
y_test = test.iloc[:, [2, 3]]前回はcsvファイルの3列目だけがアウトプットだったのですが、こちらで3, 4列目をアウトプットデータとするようにして、複数のアウトプットを得るようにします。
モデル構築
# モデルの構築
# inputの数:x1, x2
inputs = Input(shape=(2,))
# 学習回数
epochs = 100
batch_size = 64
# ノード数
node = 64
x1 = Dense(node, activation='relu')(inputs)
x2 = Dense(node, activation='relu')(x1)
x3 = Dense(node, activation='relu')(x2)
x4 = Dense(node, activation='relu')(x3) # アウトプット直前の層
output1 = Dense(1, name='output1')(x4)
x5 = Dense(node, activation='relu')(x3) # アウトプット直前の層
output2 = Dense(1, name='output2')(x5)
model = Model(inputs=inputs, outputs=[output1, output2])
optimizer = Adam(lr=0.001, beta_1=0.9, beta_2=0.999)
model.compile(
optimizer=optimizer,
loss=['mse', 'mse']
)こちらが複数出力する際のモデル部分となっておりまして、前回の記事と大きく違う部分です。
x1〜x3が全体の中間層となっておりまして、出力層の直前にも層を増やすことができるようになっています。
学習 → 予測
# 学習オプション
history = model.fit(x_train,
{"output1":y_train.iloc[:, [0]], "output2":y_train.iloc[:, [1]]},
epochs=epochs,
batch_size=batch_size,
validation_data=(x_test, {"output1":y_test.iloc[:, [0]], "output2":y_test.iloc[:, [1]]})
)上記コードを実行すると学習が始まります。
この時、output1, output2のように、出力を分けてコードを書いてあげる必要があります。
# 構築したモデルで予測
pred1, pred2 = model.predict(x_test)そして、構築したモデルを使って予測を行っていきます。
出力を2つに設定しているので、2つの予測結果を定義してあげる必要があります。
精度評価指標
#精度評価指標
# Output1 ====================================================================
print("======= Output1 =======")
# MAE
test_MAE = mean_absolute_error(y_test.iloc[:, 0], pred1)
print('MAE:', test_MAE)
# RMSE
test_RMSE = sqrt(mean_squared_error(y_test.iloc[:, 0], pred1))
print('RMSE:', test_RMSE)
# 決定係数
R2 = r2_score(y_test.iloc[:, 0], pred1)
print('R2:', R2)
print("")
# Output2 ====================================================================
print("======= Output2 =======")
# MAE
test_MAE = mean_absolute_error(y_test.iloc[:, 1], pred2)
print('MAE:', test_MAE)
# RMSE
test_RMSE = sqrt(mean_squared_error(y_test.iloc[:, 1], pred2))
print('RMSE:', test_RMSE)
# 決定係数
R2 = r2_score(y_test.iloc[:, 1], pred2)
print('R2:', R2)前回と考え方はほとんど変わりませんが、出力ごとに精度評価を求めていきます。
ちなみに、実行した時は以下のようなデータが表示されます。
======= Output1 =======
MAE: 0.014568493402845686
RMSE: 0.02438191771891204
R2: 0.999746084059966
======= Output2 =======
MAE: 0.026114249215486232
RMSE: 0.04091308209321728
R2: 0.9992200429789503損失関数グラフの可視化
# Figureを追加
fig = plt.figure(figsize = (15, 5))
# Output1 ====================================================================
# 1×2 の1枚目に描画する
loss_graph1 = fig.add_subplot(1, 2, 1)
# x,yに要素追加
loss1 = history.history['output1_loss']
val_loss1 = history.history['val_output1_loss']
epochs1 = len(loss1)
# グラフ設定
loss_graph1.plot(range(epochs), loss1, marker='.', label='loss')
loss_graph1.plot(range(epochs), val_loss1, marker='.', label='val_loss')
loss_graph1.set_title("Loss_Output1", size = 18)
loss_graph1.legend(loc='best')
loss_graph1.grid()
loss_graph1.set_xlabel("epochs", size = 14, color = "r")
loss_graph1.set_ylabel("loss", size = 14, color = "r")
#==============================================================================
# Output2 ====================================================================
# 1×2 の2枚目に描画する
loss_graph2 = fig.add_subplot(1, 2, 2)
# x,yに要素追加
loss2 = history.history['output2_loss']
val_loss2 = history.history['val_output2_loss']
epochs2 = len(loss2)
# グラフ設定
loss_graph2.plot(range(epochs), loss2, marker='.', label='loss')
loss_graph2.plot(range(epochs), val_loss2, marker='.', label='val_loss')
loss_graph2.set_title("Loss_Output2", size = 18)
loss_graph2.legend(loc='best')
loss_graph2.grid()
loss_graph2.set_xlabel("epochs", size = 14, color = "r")
loss_graph2.set_ylabel("loss", size = 14, color = "r")
#==============================================================================損失関数のグラフも出力ごとに描画してあげましょう。
なお、実際にプロットされたグラフは以下の通り。
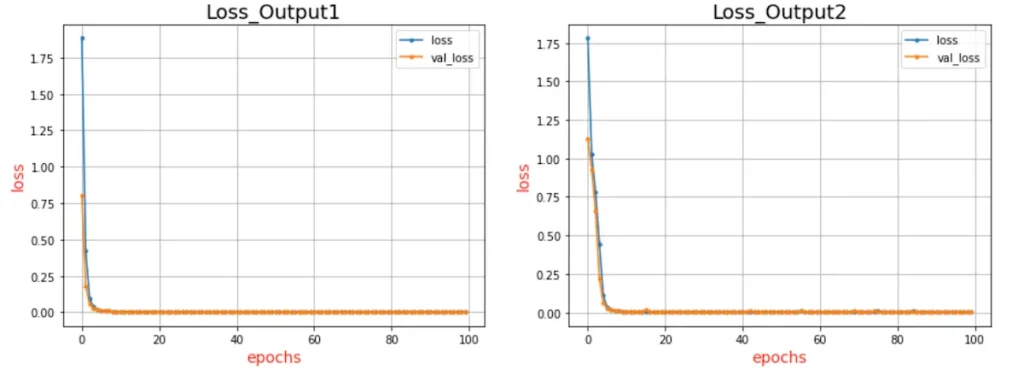
Observed-Predicted Plot
# Observed-Predicted Plot
# Figureを追加
fig = plt.figure(figsize = (15, 5))
# Output1 ====================================================================
# 1×2 の1枚目に描画する
yy1 = fig.add_subplot(1, 2, 1)
yy1.scatter(y_test.iloc[:, 0], pred1, c='blue', alpha=0.8)
# グラフ設定
yy1.set_title("observed_predicted1", size = 18)
yy1.grid()
yy1.set_xlabel("observed_data", size = 14, color = "r")
yy1.set_ylabel("predicted_data", size = 14, color = "r")
# Output2 ====================================================================
# 1×2 の2枚目に描画する
yy2 = fig.add_subplot(1, 2, 2)
yy2.scatter(y_test.iloc[:, 1], pred2, c='blue', alpha=0.8)
# グラフ設定
yy2.set_title("observed_predicted2", size = 18)
yy2.grid()
yy2.set_xlabel("observed_data", size = 14, color = "r")
yy2.set_ylabel("predicted_data", size = 14, color = "r")最後に、実データとの当てはまりの良さを調べるために、横軸に実測値を、縦軸に予測値をとったグラフをプロットします。
実際にプロットされたグラフは以下の通り。
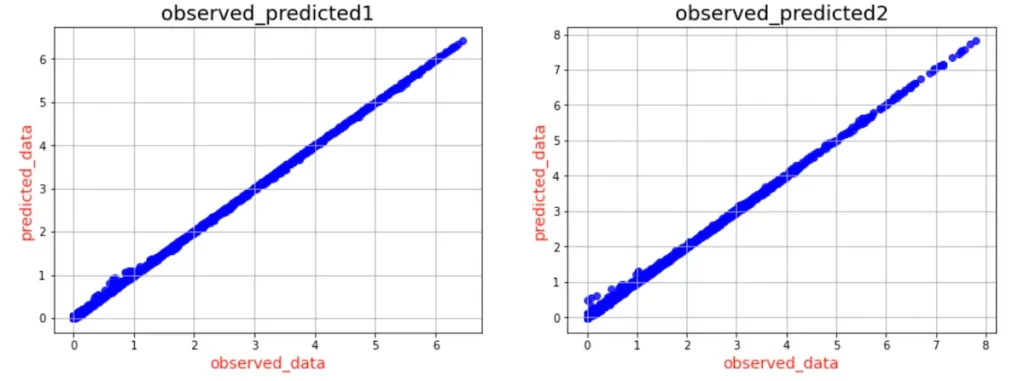
良い感じに予測できていることがわかります。
Kerasで複数出力する回帰モデルのまとめ

本記事では、Functional APIを使ってKerasで複数出力する回帰モデルを構築していきました。
前回の記事も参考にしつつ、Kerasで複数出力するモデルを作りたい方はぜひ実装してみてください。
また、以下の記事では機械学習に関する情報などをゆるくアウトプットしているので、あわせて見ていただけると嬉しいです〜

-300x250.webp)

